College News
Bias in the System
How do algorithms perpetuate discrimination, and what can we do to fix it?
Technology has the possibility to change the world. We often hear stories of people using Twitter and Facebook to fight for democracy, getting an education through online courses or applying big data to solve public health problems. However, we must not assume that technology is inherently good. Computer systems can contain the same biases as humans, and as programmers we must know how to detect and fix these biases.
I believe that as computer scientists it is our job to think about the impact of our work. There is a significant lack of critical thinking about the possible negative impacts of computer science, so I decided to research how algorithms learn to discriminate.
There’s bias in algorithms?
Algorithms can appear free of bias because they remove human influence. Whereas previously a bank teller handling your loan application might be swayed by their first impressions, a computer program is not affected by appearance. The fact that a human is not making the decision makes the program appear objective, but humans are not removed from programs. People write the algorithms, find the initial data and interact with the program, all of which provide opportunities for bias to creep in.
Why should we care about bias in algorithms? As programmers we spend a lot of time thinking about the best algorithm for a particular problem, but spend less time thinking about the impact the program might have. If our algorithms are discriminating then we are directly responsible for their harm. It is important to learn how to detect discrimination so we can reduce any negative impact of our work.
What are biases and algorithms?
Bias as defined by Merriam Webster, is “a tendency to believe that some people, ideas, etc., are better than others.” Bias isn’t always bad; if you believe Mexican food is the best type of food, then you have a bias. However, if bias takes the form of an unfair preference that is routinely acted upon, it’s known as discrimination.
Although people sometimes actively discriminate due to their own biases, implicit bias is much more common than active discrimination. In these situations, people unconsciously discriminate due to pressures in society. For example, in a recent study, researchers repeatedly applied for a lab manager position (a stereotypically male role), where they kept the content of the applications the same but changed the name and gender. In feedback, the women were ranked lower in competence, hireability and willingness to mentor and were also offered a lower salary. Since the content of the applications was the same, these differences were solely based on gender. The men and women who ranked these applications did not intentionally prefer men, rather societal stereotypes about who’s a better fit for the role unintentionally affected their decisions. This is implicit bias.
Next, let’s talk about algorithms; they’re really just a set of steps to solve a problem. When I was an underclassman the word “algorithms” scared me. I thought that I couldn’t write algorithms till I’d taken my school’s algorithms course. But if you’ve ever written a computer program that was meant to give you an answer or solve a particular problem, then you’ve written an algorithm!
How algorithms discriminate
So can implicit bias affect computer algorithms? Any time humans interact with programs they have the potential to influence them, and this influence may be unintentional. People interact with algorithms during development, through the data those algorithms access and when the programs interact with users. Let’s see how bias can occur in each of these stages of the algorithm.
Development
An algorithm starts off in development where bias can affect programming decisions. When two options seem equally rational or multiple algorithms could be used, you are required to use your values to judge which option is best. Your bias could influence this decision. While your choice is not necessarily discriminatory, your bias could cause a problematic outcome. The choices developers make could provide an opportunity for implicit bias to occur.
Data
Once an algorithm has been developed, it is often trained with data. Training happens when machine learning algorithms take a bunch of data and use statistics to find trends. Machine learning algorithms then use these trends for future predictions.
Training can go wrong if, for example, a company used past hiring data to train an algorithm to select new employees, but their old hiring managers suffered from implicit bias when evaluating resumes of women. Then the algorithm will learn those trends from the data and keep discriminating. Past biased trends can easily be encoded into an algorithm through old data.
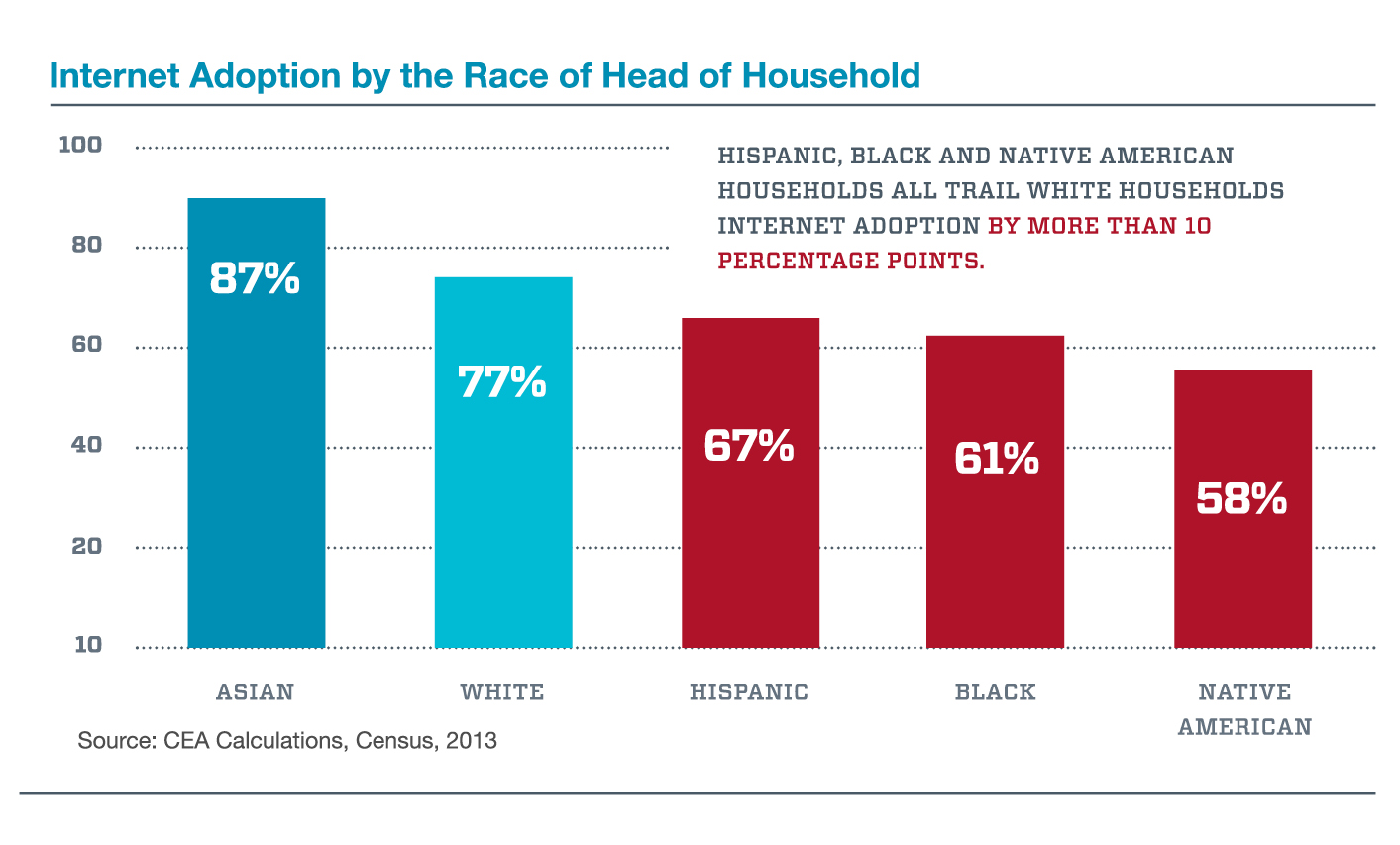
Another problem is that the data might not be representative of all groups. Boston had this problem when it developed an app that detected potholes using accelerometer data gathered by smartphones as people drove around the city. Unfortunately, the people who own smartphones are not representative of the entire population and as a result, this app focused city resources on wealthier neighborhoods.
Most algorithms are susceptible to this because, in general, wealthier people own more technology and have better internet access, which is split based on income, education, race and location. There is inherently more data about people who spend more time on the internet, and data sets that cross this divide are harder to access, less dense in information and smaller in overall size.
Another issue with machine learning algorithms is that it can be hard to know what trends the algorithm found or how it found them. Let’s say a bank is building a machine-learning system to approve loan applications and that historically this bank has unintentionally discriminated against its applicants based on race. If the data given to the algorithm includes race, the machine learning algorithm could easily find race to be an important factor in its predictions.
But even if the data does not include race, this trait is often doubly encoded in other variables, like socioeconomic status and location. So the machine learning algorithm could find a trend where it approximates race based on other variables and still perpetuates the discrimination. For example, the algorithm could find that the zip code of the applicant is an important feature to use when deciding whether to approve a loan. But if the neighborhoods in this city have significantly different racial makeups, then zip code is a proxy for race, and the algorithm is still effectively using race as a factor in its decision. Using race as a part of a loan application decision is illegal.
The scary thing is that the developers might not guess the algorithm is discriminating since they removed race as a feature. So, machine learning algorithms can learn to discriminate using variables we don’t give them access to, and we might have no clue that they are discriminating.
Users
Finally, users may influence a product with their own biases. As a pertinent recent example, Microsoft released a version of a twitter bot called Tay, which quickly turned racist, misogynist and anti-Semitic by learning from user tweets. In this case, Twitter users intentionally tried to distort the bot, but any system that relies on user input is vulnerable to the impact of user choices.
Systems that rely less explicitly on users can still have problems. A recent study published in PNAS by Corinne Moss-Racusin and colleagues, asked users to rate the quality of image search results when focusing on different occupations. They found that users rated the results as having higher quality if the gender proportions of the images matched the stereotypes of who did what job (so stereotypically a search for “nurses” would have mostly images of women). This study reveals a direct conflict between the goals of improving quality and keeping results unbiased. Any system that uses users to rate results suffers from this potential for bias. But programmers do have the power to find and fix these biases.
How can we find and fix bias?
On a personal level, we should strive to be aware of the impact of the algorithms we develop. Here are some tasks we can complete to make sure we are considering our full impact:
Ask yourself questions about the impact of the software
- Will it affect everyone equally?
- Will two users from different backgrounds have a different experience with the software? If so, is the experience fair to both?
- Will all people have equal access to it?
- What is needed to access this technology (a certain device, knowing English, specific jargon)? Is this technology available to all?
- Will it work better for some groups over others?
- Is the program optimized for some set of data? Is that data representative?
- Does it require any prior knowledge? Does everyone have equal access to that prior knowledge?
- Is it resilient to attacks by trolls on the internet?
Run tests with all demographics of users and user data
- One of the best ways to answer the questions above is to run tests. If your application uses profiles of any kind, try running many profiles changing the traits slightly each time. For example, you could change the name to be more masculine or feminine or of a different ethnicity, or change the age of the profile. To make this easier, there are random name generators that can generate names across gender and ethnic spectrums.
- You can also ask a diverse set of people to try the software and ask them to be hyper-aware of any assumptions it makes.
In some cases it may not be possible to reach full equality, but we should do our best. One metric is to remove inequality from the code we work on directly. For example, we might not be able to get data across the digital divide, but we can make sure our data is as representative as possible.
We can also encourage our institutions to consider their impact. Companies can develop frameworks that make auditing their software easier. Auditing is the process of submitting different user profiles to a system and seeing if the results change in a way that is problematic (e.g., see if changing a name to make it more feminine gives different, discriminatory search results).
Externally, companies and institutions can produce ethics policies. Much like companies currently produce privacy policies that dictate what they will never do with user data, companies can clearly state what sort of ethical standards they have adopted for their software. This would keep companies accountable for their systems. Academic institutions should produce similar statements. “It’s just research” is not an excuse for ignoring these problems.
Technology really does have the possibility to change the world. However, as programmers, we have a responsibility to think about all the impacts of our software. We must be vigilant to the ways that algorithms can perpetuate the discrimination already present in society and work to remove bias from our algorithms.
—
Paige Garratt ’16 is a computer science alumna. She completed this research in an independent study with the help of computer science Professor Ben Wiedermann during her last semester to bring together her interests in computer science and social justice.